简介
1).MySQL中的全文索引是FultLeXT类型的索引。 2).全文索引只能用于InnoDB或MyISAM表,只能为CHAR、VARCHAR、TEXT列创建。 3).在MySQL 5.7.6中,MySQL提供了支持中文、日文和韩文(CJK)的内置全文ngram解析器,以及用于日文的可安装MeCab全文解析器插件 4).当创建表时,可以在CREATE TABLE语句中给出FULLTEXT索引定义,或者稍后使用ALTER TABLE或CREATE INDEX添加该定义。 5).对于大型数据集,将数据加载到没有FULLTEXT索引的表中然后创建索引要比将数据加载到具有现有FULLTEXT索引的表中快得多。全文索引的三种类型
- 自然语言搜索将搜索字符串解释为自然语言中短语。
- 布尔全文搜索
- 查询扩展搜索
配置 my.ini配置文件中添加
# MySQL全文索引查询关键词最小长度限制 [mysqld] ft_min_word_len = 1 保存后重启MYSQL,执行SQL语句数据结构: 倒排索引
例子:
-- 创建索引 CREATE TABLE test(title VARCHAR(40),FULLTEXT(title));-- 插入数据INSERT INTO testVALUES('Some like it hot, Some like it cold'),('Some like it in the pot'),('Nine days old'),('Pease porridge in the pot'),('Pease porridage hot, pease porridge cold'),('Nine days old'); 然后查看一下information_schema下的INNODB_FT_INDEX_TABLE表.如果不允许访问
就设置一下:SET GLOBAL innodb_ft_aux_table = 'test/test';
然后再查看一下INNODB_FT_INDEX_TABLE或者INNODB_FT_INDEX_CACHE表
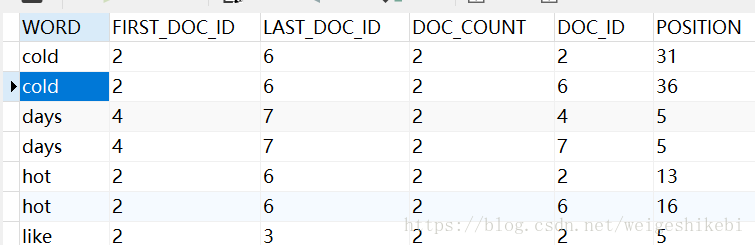
会出现类似的记录,表明已经建立了映射关系
Innodb采用的是full inverted index的存储方式。这种方式会占用更多的空间,因为它不仅会存储单词和单词所在文档的ID,还会存储单词所在文档的ID中具体的位置。可以用一个简单的表格来解释
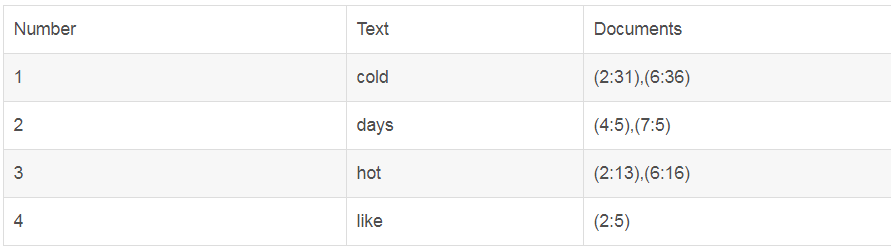
相对的,还有一种存储方式:inverted file index,只存储单词及对应的单词所在文档。这种理节省空间,但是查找时,只能根据关键字得到相应文档,现进行查找
分词
通过上面的例子,我们发现,innodb会把单词拆分进行存储,查找时,根据单词匹配(默认是英文符号)但是有一些词,我们可能是不能索引查询的,比如'to',这称之为stopword;
-- 默认停止词 SELECT * FROM information_schema.INNODB_FT_DEFAULT_STOPWORD;
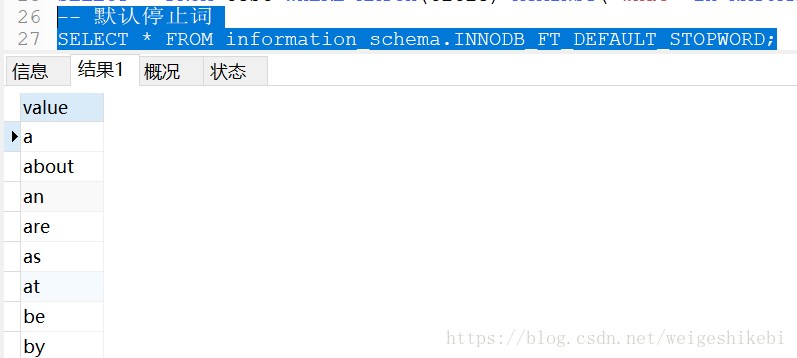
或者word的字符长度不在innodb_ft_min_token_size到innodb_ft_max_token_size。默认是3-84个字符区间
INSERT INTO test VALUES-- 90字符('123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890'),-- 80字符('12345678901234567890123456789012345678901234567890123456789012345678901234567890'); 插入一个80,90的字符长度,会现在只有80的字符被分词了:INNODB_FT_INDEX_CACHE表可查,
同理,也只有80的字符记录被索引
SELECT * FROM testWHERE MATCH(title) AGAINST('12345678901234567890123456789012345678901234567890123456789012345678901234567890'); 当然,也可以定制stopword,可以参考mysql stopwords
相关性
如果一个查询,匹配到多条记录,是怎么返回呢?根据相关性-- 查询相关性SELECT title, MATCH(title) AGAINST('like') AS relevance FROM test 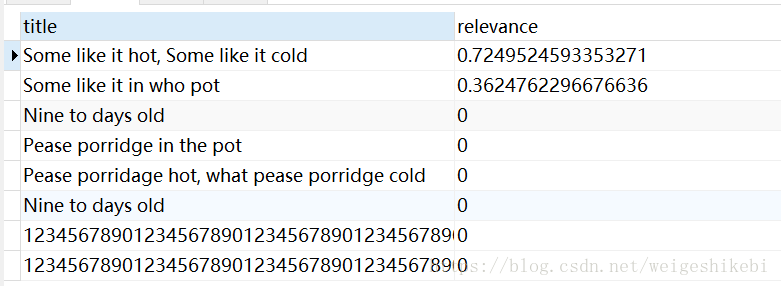
发现只有前面2条记录的相关性>0,推断查询结果就是取相关性>0的记录,其实也正是如此。那相关性是怎么计算呢
(1) word(查询关键字)是否在文档中出现
(2) word在文档中出现的次数 (3) word在索引列中的数量 (4) 多少个文档包含该word所以Some like it hot, Some like it cold,出现了2次like,相关性高Some like it in who pot出现了1次,相关性低
而其它记录没有相关性
检索模式
Natural Language 上面的例子我们是用的默认的检索模式,Natural Language模式!表示查询带有指定word的文档。下面2种方式是等价的SELECT * FROM test WHERE MATCH(title) AGAINST('what' in NATURAL LANGUAGE MODE);SELECT * FROM test WHERE MATCH(title) AGAINST('what'); SELECT * FROM test WHERE MATCH(title) AGAINST('+Pease' in BOOLEAN MODE); 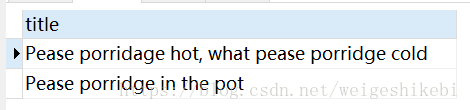
假设,我们需要查找有Pease,但是没有hot的记录呢?用+,-符号,分别表示一定存在,或者一定不存在
SELECT * FROM test WHERE MATCH(title) AGAINST('+Pease -hot' in BOOLEAN MODE);
出处:https://blog.csdn.net/weigeshikebi/article/details/80342726